The Java Data Processing Framework (JDPF) helps you in the definition, generation and execution of standard and custom data processing. JDPF has been designed to be modular and estendable. For these reasons, we decided to implement it in Java™ through OSGi technology which provides a service-oriented, component-based environment for developers and offers standardized ways to manage the software lifecycle.

JDPF can be used for defining your own data analysis procedure reusing already provided modules or developing your own solutions. Briefly, the data processing is performed by 'components' (or nets) that are composed by a pipeline of reusable 'modules' (or blocks). Modules are developed on the top of the JDPF framework. Data flow through the pipeline embedded in suitable data types. You can read more about the components structure and definition here.
Core Concepts
JDPF is build around the pipeline concept. A pipeline (Fig. 1) is a set of data processing elements, that we call blocks or modules, connected in series, so that the output of one element is the input of the next one.

Figure 1 - The generic pipeline model
Each block represents an operator defining the relation between an element x of a set X (the domain) and a unique element y of a set Y (the codomain) through a parameterization p of the embedded algorithm (Fig. 2). The parameterization allows decoupling the pipeline from the context as better explained later on. In most of the cases, X and Y can be given the mathematical structure of metric spaces.
Figure 2 - The generic block which implements an operator A from a domain X to a codomain Y through a parameterization in P
Pipelines
The pipeline in JDPF can be composed organizing sequentially two different kind of blocks:
- Filters: They give an output defined within the same metric space of the input. Examples are blocks embedding outliers filtering in a time series as well as noise reduction algorithm for images;
- Transformers: Their output metric space is different from the input one. Examples can be a mechanism for qualitative abstraction performing quantitative data mapping into symbolic values as well as algorithms for the transformation at a different color depth of an image.
Figure 3 - Symbols for the filter and the transformer
Each block must be provided with a descriptor that specifies the type of input/output data the block can accept, as well as the set of accepted/needed parameters. A pipeline can be built by assembling different blocks according to the constraints defined by the descriptors.
Figure 4 - An example of pipeline, a sequence of blocks
Nets
In order to process multiple data streams, JDPF provides also another couple of blocks:
- Splits, they accept a single data stream in input and give two data streams in output.
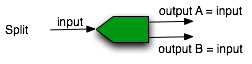
Figure 5 - Symbol for the split
- Aggregators (or joins), which accept as input the data coming from two different pipelines and give as output a single data stream derived from the application of an operator tuned, as usual, through a set of parameters
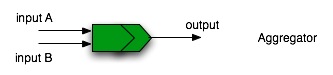
Figure 6 - Symbol for the aggregator
A net is a collection of blocks organized not simply in a sequence but in a network that uses splits and/or joins.
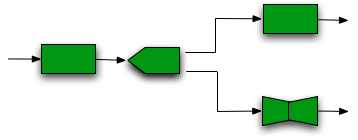
Figure 7 - Example of net
Components
When the pipeline or nets have been defined, it is needed to transform them into JDPF components that represent complete data processing elements. A component, when deployed in the JDPF engine, is able to fetch the data feeding the pipeline and store its results. This is possible by adding to the pipeline two kind of blocks:
- Generators: they provide the input to the pipeline out of binary data (xml, images, text, html, zip) or other kind of sources such as specific tables in a relational database;
- Serializers: they represent the end of the pipeline and transform the pipeline content into data in different binary formats (xml, images, text, html, zip, pdf) or into tables of a relational database;
Figure 8 - Symbols for the generator and the serializer
Figure 9 - A simple example of pipeline component defined by the sequence: generator, filter, transformer, filter and serializer
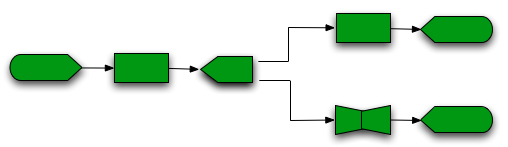
Figure 10 - A simple example of net component
Inspection
In order to be able to inspect data flowing in the components, we defined the blocks:
- Inspectors: they give a numeric or graphical view of the data flowing in the pipeline. These blocks don’t perform any filtering nor transformation of data, they simply generate a view of the pipeline content. Such depiction can be serialized for instance as a set of images that will be stored as they are, inside a document or in relational database tables.
Figure 11 - A simple example of component (defined by the sequence: generator, filter, transformer, filter and serializer) with two different inspectors
Parameters/Context
Since JDPF is conceived to provide a general purpose environment, the contextualization of the data processing components has been intentionally held out of the component scope. Our idea is that an external context manager should be used to determine the set of parameters for the blocks configurations. This solution guarantees, on one side, the independence of the algorithms from the context complexity and, on the other one, the possibility of reusing the same pipeline and/or component in different application contexts. Each time a component is run, it must receive the parameters for each component block.
References
[1] Ciccarese Paolo, Larizza C. A Framework for Temporal Data Processing and Abstractions. AMIA (American Medical Informatics Association) 2006 Annual Symposium. Presented in Washington DC, USA on November 12, 2006 - PubMed, PubMed Central
[2] Larizza C, Ciccarese Paolo. An Extensible Software Framework for Temporal Data Processing. IDAMAP (Intelligent Data Analysis in bioMedicine And Pharmacology) 2007. Presented in Amsterdam, Netherlands on July 8, 2007 - Proceedings
[3] Ciccarese Paolo, Larizza C. Framework for temporal data processing and abstractions. I Workshop on Technologies for Healthcare and Healthy Lifestyle. Presented in Valencia, Spain on April 6, 2006